Unicorn简介
准备Unicorn模拟执行
导入相应的库并对UC模拟器进行初始化,下面是一个很简单的实例
from unicorn import *
#导入相应架构的常量
from unicorn.arm_const import *
from unicorn.arm64_const import *
from unicorn.m68k_const import *
from unicorn.mips_const import *
from unicorn.sparc_const import *
from unicorn.x86_const import *
ARM_CODE = b"\x37\x00\xa0\xe3\x03\x10\x42\xe0"
def hook_code(uc,address,size,user_data):
print("Tracing at 0x%x , The size is 0x%x" %(address,size))
def start_unicorn():
print('Start!!')
try:
#创建模拟器,前一个为UC_ARCH_架构,后面是UC_MODE_指令集对应的位数或模式
#mu = UC(UC_ARCH_X86,UC_MODE_64)
mu = Uc(UC_ARCH_ARM,UC_MODE_THUMB)
#开辟内存并对其进行填充(注意memmap的时候要0x1000进行对齐)开了2MB
address = 0x10000
mu.mem_map(address, 2 * 0x100000)
mu.mem_write(address,ARM_CODE)
#对寄存器进行初始化,UC_架构_REG_寄存器的名字
mu.reg_write(UC_ARM_REG_R0,0x1234)
mu.reg_write(UC_ARM_REG_R2,0x4321)
mu.reg_write(UC_ARM_REG_R3,0x3333)
#对每一条指令进行hook,地址其实是没有必要进行填入的,hook_code是对每一条指令进行的hook函数
mu.hook_add(UC_HOOK_CODE,hook_code,begin=address,end=address+len(ARM_CODE))
mu.emu_start(address,address+len(ARM_CODE))
r0 = mu.reg_read(UC_ARM_REG_R0)
r1 = mu.reg_read(UC_ARM_REG_R1)
print(f"R0 is {r0}")
print(f"R1 is {r1}")
except UcError as e:
print("Error is %s" % e)
if __name__ == "__main__":
start_unicorn()重要函数简介
hook_add 函数可以为指定的代码范围添加callback 是的每一条指令的执行前后都有机会去进行hook,其中htype为hook的类型,callback为handler,user_data为附加参数,begin和end为hook作用的起始地址和结束地址
def hook_add(self, htype, callback, user_data=None, begin=1, end=0, arg1=0):
pass在callback中我们能拿到当前执行的地址(address)和当前指令的长度(size)和设置的参数(user_data),而且有了uc虚拟机指针可以访问各种寄存器,并且修改PC寄存器来改变流程
与Unicorn一样capstone也是需要两个参数,一个是ARCH另一个MODE,disasm第一个参数是code要反编译的字节码,第二个是代码块的起始位置,会返回一个capstone.CsInsn对象的迭代器,里面有每一条反汇编的指令
self.md = Cs(CS_ARCH_X86, CS_MODE_64)
dis = self.md.disasm(mu.mem_read(address, size), address))
#for i in dis:
# print(f"0x{i.address:x}:\t{i.mnemonic}\t{i.op_str}")
#访问i的不同成员会得到类似下面的地址、操作码、操作数等信息
# #0x1000: push rbp
# #0x1001: mov rdi, qword ptr [rip + 0x13b8]
天堂之门WP
天堂之门是一种在32位程序上运行64位代码的技术,32位WoW64进程中执行64位代码,以及直接调用WIN32 API函数的技术,用于干扰静态分析,避免API的Hook,绕过对WIN32 API的检测
这篇文章很清楚的说明了天堂之门的实现WoW64 internals | mindless-area
jmp far 这个大跳被ida识别错了,应该是调到0x405310的位置然后将运行的系统改为64位的,然后下面的将 0x23 压入栈中,然后 retf 返回的时候将系统又改回32位的,并通过返回的值进行判断 flag
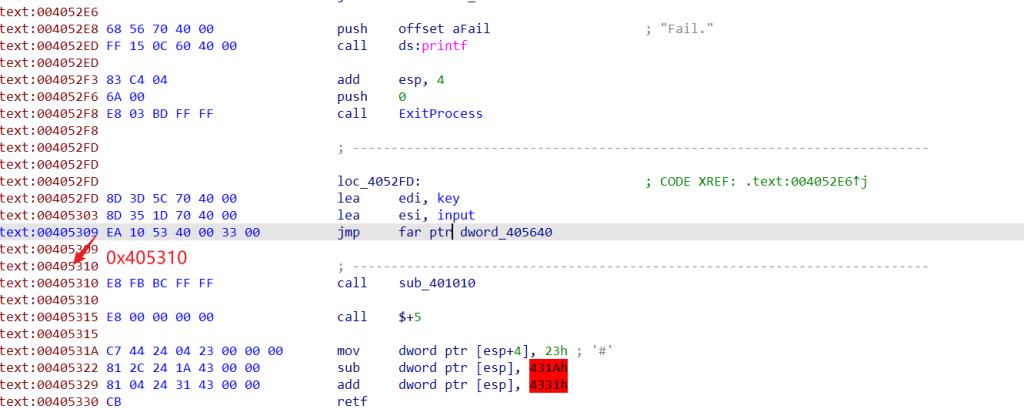
当然可以用64位的ida看到函数 sub_401010 中的逻辑,会发现有大量的花指令(而且是不同种类的),这里就可以用到Unicorn来进行模拟执行
import itertools
from unicorn import *
from unicorn.x86_const import *
with open('./OddCode.exe','rb') as fp:
fp.seek(0x400)
X86_CODE = fp.read(0x5000)
class UniVM:
def __init__(self,flag):
mu = Uc(UC_ARCH_X86, UC_MODE_64)
address = 0xC51000
LocIns_Addr = 0
Pre_Ins_Size = 0
Save_Rip = []
Nums = 0
self.flag = flag
self.mu = mu
self.Save_Rip = Save_Rip
self.LocIns_Addr = LocIns_Addr
self.Pre_Ins_Size = Pre_Ins_Size
self.address = address
self.Nums = Nums
self.F = False
mu.mem_map(address, 0x1000000)
mu.mem_write(address, X86_CODE)
mu.reg_write(UC_X86_REG_RAX, 1)
mu.reg_write(UC_X86_REG_RBX, 0x008F102D)
mu.reg_write(UC_X86_REG_RCX, 0x4B141F37)
mu.reg_write(UC_X86_REG_RDX, 0x00000001)
mu.reg_write(UC_X86_REG_RSI, 0x00C5701D)
mu.reg_write(UC_X86_REG_RDI, 0x00C5705C)
mu.reg_write(UC_X86_REG_RBP, 0x00B8F848)
mu.reg_write(UC_X86_REG_RIP, 0x00B8F838)
mu.reg_write(UC_X86_REG_RSP, 0x00C55309)
mu.reg_write(UC_X86_REG_FLAGS,0x00000202)
mu.mem_write(self.address + 0x605C, b'\x90\xF0\x70\x7C\x52\x05\x91\x90\xAA\xDA\x8F\xFA\x7B\xBC\x79\x4D')
mu.mem_write(self.address + 0x601D,self.flag)
print(self.flag)
mu.hook_add(UC_HOOK_CODE,self.hook_code,begin=address,end=address+len(X86_CODE))
mu.hook_add(UC_HOOK_MEM_READ,self.read_mem)
def hook_code(self,mu,address,size,user_data):
if abs(address - self.LocIns_Addr) > self.Pre_Ins_Size:
self.Save_Rip.append(address)
self.Nums += 1
self.LocIns_Addr = address
self.Pre_Ins_Size = size
def read_mem(self,mu,access,address,size,value,data):
if address >= self.address + 0x605C and address <= self.address + 0x605C + 15:
print(f"Read key[{address - (self.address + 0x605C)}] at {hex(mu.reg_read(UC_X86_REG_RIP))}")
if address >= self.address + 0x601D and address <= self.address + 0x601D + 41:
print(f"Read flag[{address - (self.address + 0x601D)}] at {hex(mu.reg_read(UC_X86_REG_RIP))}")
if (address - (self.address + 0x601D)) == 10:
#print(self.flag)
#raise ValueError("Find something")
self.F = True
return
def start(self):
try:
self.mu.emu_start(self.address+0x10,self.address+len(X86_CODE))
except UcError as e:
print(f"Error is {e}")
if self.F == True:
return True
else:
return False
# count = 0
# for i in self.Save_Rip:
# if not count%10:
# print()
# print(hex(i), end=',')
# count += 1
# self.mu.emu_stop()
tmp_flag = bytearray(b'SangFor{11111111111111111111111111111111}')
# table = b'0123456789ABCDEFabcdef'
# for i in range(16):
# for j in itertools.product(table,repeat=2):
# tmp_flag[2*i+8] = j[0]
# tmp_flag[2*i+9] = j[1]
# if UniVM(bytes(tmp_flag)).start() == True:
# print(tmp_flag)
# continue
print(tmp_flag)
UniVM(bytes(tmp_flag)).start()执行一遍发现对输入的前两位进行了访问
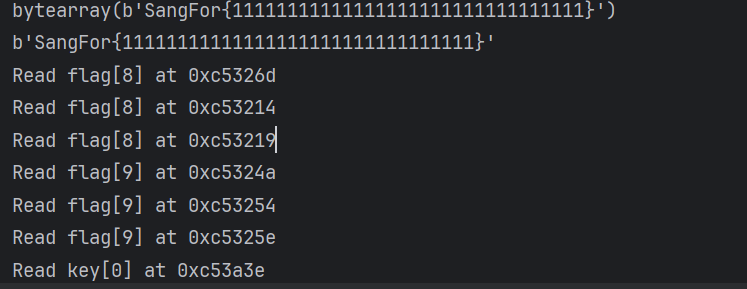
现将前两位爆破出来
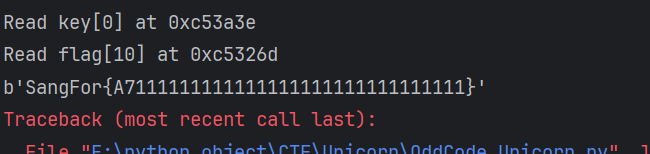
发现对后面的数据进行了访问,猜测是两位一组,可以爆破,参考了大佬的WP,一种是通过是否检验下一位(最后两位需要再分类),另一种是找到最终test的位置
第一种
import itertools
from unicorn import *
from unicorn.x86_const import *
with open('./OddCode.exe','rb') as fp:
fp.seek(0x400)
X86_CODE = fp.read(0x5000)
class UniVM:
def __init__(self,flag,Round):
mu = Uc(UC_ARCH_X86, UC_MODE_64)
address = 0xC51000
LocIns_Addr = 0
Pre_Ins_Size = 0
Save_Rip = []
Nums = 0
self.flag = flag
self.mu = mu
self.Save_Rip = Save_Rip
self.LocIns_Addr = LocIns_Addr
self.Pre_Ins_Size = Pre_Ins_Size
self.address = address
self.Nums = Nums
self.F = False
self.round = Round
mu.mem_map(address, 0x1000000)
mu.mem_write(address, X86_CODE)
mu.reg_write(UC_X86_REG_RAX, 1)
mu.reg_write(UC_X86_REG_RBX, 0x008F102D)
mu.reg_write(UC_X86_REG_RCX, 0x4B141F37)
mu.reg_write(UC_X86_REG_RDX, 0x00000001)
mu.reg_write(UC_X86_REG_RSI, 0x00C5701D)
mu.reg_write(UC_X86_REG_RDI, 0x00C5705C)
mu.reg_write(UC_X86_REG_RBP, 0x00B8F848)
mu.reg_write(UC_X86_REG_RIP, 0x00B8F838)
mu.reg_write(UC_X86_REG_RSP, 0x00C55309)
mu.reg_write(UC_X86_REG_FLAGS,0x00000202)
mu.mem_write(self.address + 0x605C, b'\x90\xF0\x70\x7C\x52\x05\x91\x90\xAA\xDA\x8F\xFA\x7B\xBC\x79\x4D')
mu.mem_write(self.address + 0x601D,self.flag)
print(self.flag)
mu.hook_add(UC_HOOK_CODE,self.hook_code,begin=address,end=address+len(X86_CODE))
mu.hook_add(UC_HOOK_MEM_READ,self.read_mem)
def hook_code(self,mu,address,size,user_data):
if abs(address - self.LocIns_Addr) > self.Pre_Ins_Size:
self.Save_Rip.append(address)
self.Nums += 1
self.LocIns_Addr = address
self.Pre_Ins_Size = size
def read_mem(self,mu,access,address,size,value,data):
if address >= self.address + 0x605C and address <= self.address + 0x605C + 15:
print(f"Read key[{address - (self.address + 0x605C)}] at {hex(mu.reg_read(UC_X86_REG_RIP))}")
if address >= self.address + 0x601D and address <= self.address + 0x601D + 41:
print(f"Read flag[{address - (self.address + 0x601D)}] at {hex(mu.reg_read(UC_X86_REG_RIP))}")
if (address - (self.address + 0x601D)) == 10 + 2 * self.round:
# print(self.flag)
# raise ValueError("Find something")
self.F = True
self.mu.emu_stop()
def start(self):
try:
self.mu.emu_start(self.address+0x10,self.address+len(X86_CODE))
except UcError as e:
print(f"Error is {e}")
if self.F == True:
return True
else:
return False
# count = 0
# for i in self.Save_Rip:
# if not count%10:
# print()
# print(hex(i), end=',')
# count += 1
# self.mu.emu_stop()
tmp_flag = bytearray(b'SangFor{11111111111111111111111111111111}')
table = b'0123456789ABCDEFabcdef'
for i in range(16):
for j in itertools.product(table,repeat=2):
tmp_flag[2*i+8] = j[0]
tmp_flag[2*i+9] = j[1]
if UniVM(bytes(tmp_flag),i).start() == True:
print(tmp_flag)
break
print(tmp_flag)最后有两位是爆破不出来的,我尝试通过address判断不知道为什么总是跳不出来,可能是转为32位部分之后64Unicorn模拟不了
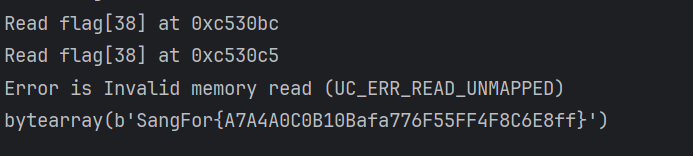
另写了一个爆破的脚本
import itertools
import subprocess
flag = bytearray(b'SangFor{A7A4A0C0B10Bafa776F55FF4F8C6E811}')
table = b'0123456789ABCDEFabcdef'
for j in itertools.product(table,repeat=2):
path = './OddCode.exe'
flag[-3] = j[0]
flag[-2] = j[1]
p = subprocess.Popen(path,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
text=True)
stdout,_=p.communicate(input=flag.decode())
if "Success" in stdout:
print(flag)
第二种
配合capstone,找到检测的位置
mu.hook_add(UC_HOOK_CODE,self.check_cmp)
def check_cmp(self,mu,address,size,user_data):
md = Cs(CS_ARCH_X86, CS_MODE_64)
dis = md.disasm(self.mu.mem_read(address,size),address)
for i in dis:
if 'cmp' in i.mnemonic or 'test' in i.mnemonic:
print(f"{hex(address)} was use {i.mnemonic} size is {size}")发现在使用key进行加密之后只有一个cmp,猜测在这里进行每一轮最后的比对
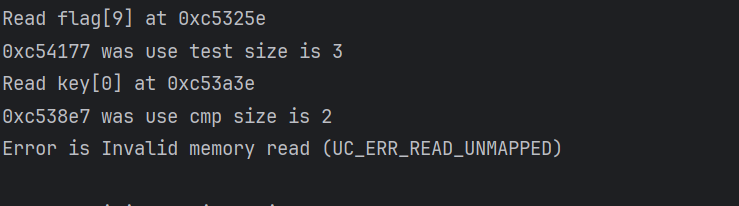
找到相应位置
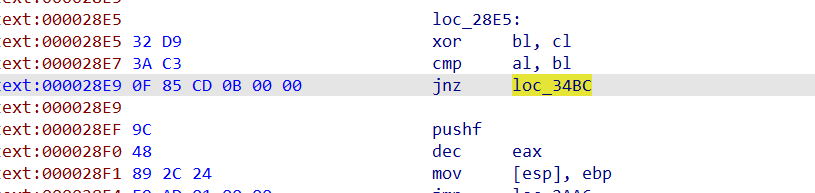
走到 0xc538ef 即可
import itertools
from capstone import *
from unicorn import *
from unicorn.x86_const import *
with open('./OddCode.exe','rb') as fp:
fp.seek(0x400)
X86_CODE = fp.read(0x5000)
class UniVM:
def __init__(self,flag,Round):
mu = Uc(UC_ARCH_X86, UC_MODE_64)
address = 0xC51000
LocIns_Addr = 0
Pre_Ins_Size = 0
Save_Rip = []
Nums = 0
self.flag = flag
self.mu = mu
self.Save_Rip = Save_Rip
self.LocIns_Addr = LocIns_Addr
self.Pre_Ins_Size = Pre_Ins_Size
self.address = address
self.Nums = Nums
self.F = False
self.round = Round
self.count = 0
mu.mem_map(address, 0x1000000)
mu.mem_write(address, X86_CODE)
mu.reg_write(UC_X86_REG_RAX, 1)
mu.reg_write(UC_X86_REG_RBX, 0x008F102D)
mu.reg_write(UC_X86_REG_RCX, 0x4B141F37)
mu.reg_write(UC_X86_REG_RDX, 0x00000001)
mu.reg_write(UC_X86_REG_RSI, 0x00C5701D)
mu.reg_write(UC_X86_REG_RDI, 0x00C5705C)
mu.reg_write(UC_X86_REG_RBP, 0x00B8F848)
mu.reg_write(UC_X86_REG_RIP, 0x00B8F838)
mu.reg_write(UC_X86_REG_RSP, 0x00C55309)
mu.reg_write(UC_X86_REG_FLAGS,0x00000202)
mu.mem_write(self.address + 0x605C, b'\x90\xF0\x70\x7C\x52\x05\x91\x90\xAA\xDA\x8F\xFA\x7B\xBC\x79\x4D')
mu.mem_write(self.address + 0x601D,self.flag)
print(self.flag)
mu.hook_add(UC_HOOK_CODE,self.hook_code,begin=address,end=address+len(X86_CODE))
mu.hook_add(UC_HOOK_MEM_READ,self.read_mem)
# mu.hook_add(UC_HOOK_CODE,self.check_cmp)
#
# def check_cmp(self,mu,address,size,user_data):
# md = Cs(CS_ARCH_X86, CS_MODE_64)
# dis = md.disasm(self.mu.mem_read(address,size),address)
# for i in dis:
# if 'cmp' in i.mnemonic or 'test' in i.mnemonic:
# print(f"{hex(address)} was use {i.mnemonic} size is {size}")
def hook_code(self,mu,address,size,user_data):
if abs(address - self.LocIns_Addr) > self.Pre_Ins_Size:
self.Save_Rip.append(address)
self.Nums += 1
self.LocIns_Addr = address
self.Pre_Ins_Size = size
if address == 0xc538ef:
self.count += 1
if self.count == self.round + 1:
self.F = True
self.mu.emu_stop()
def read_mem(self,mu,access,address,size,value,data):
if address >= self.address + 0x605C and address <= self.address + 0x605C + 15:
print(f"Read key[{address - (self.address + 0x605C)}] at {hex(mu.reg_read(UC_X86_REG_RIP))}")
if address >= self.address + 0x601D and address <= self.address + 0x601D + 41:
print(f"Read flag[{address - (self.address + 0x601D)}] at {hex(mu.reg_read(UC_X86_REG_RIP))}")
def start(self):
try:
self.mu.emu_start(self.address+0x10,self.address+len(X86_CODE))
except UcError as e:
print(f"Error is {e}")
if self.F == True:
return True
else:
return False
tmp_flag = bytearray(b'SangFor{11111111111111111111111111111111}')
table = b'0123456789ABCDEFabcdef'
for i in range(16):
for j in itertools.product(table,repeat=2):
tmp_flag[2*i+8] = j[0]
tmp_flag[2*i+9] = j[1]
if UniVM(bytes(tmp_flag),i).start() == True:
print(tmp_flag)
break
print(tmp_flag)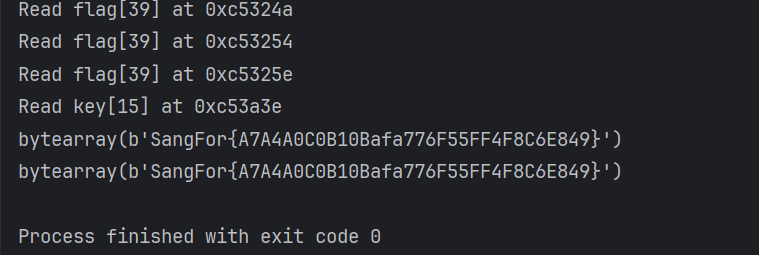
完结撒花,Unicorn确实很好用,hook指令还是太好用了,而且可以“叠加”Hook,配合capstone还能再玩些操作,很好的Unicorn使我的大脑旋转。