前言
正则表达式一般用不到,用到不是一般难受,别说写脚本了,用notepad++替换个字符都费老鼻子劲了
看似很复杂,其实就是几个语法,学会了确实好用
正则基础语法
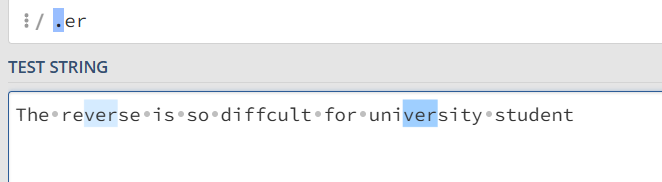
. 点运算符
用于匹配任何一个单个的字符,换行符除外
如果要搜索字符 . 需要进行转义 \.

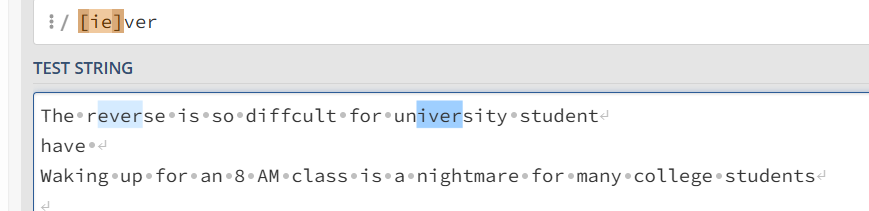
[] 字符集
用于匹配字符集中的任意一个字符 [ie]ver 可以匹配 ever 和 iver,其他的就不能匹配了
注意 许多语法的符号在字符集中会被默认认定为 字符而不能进行相应的作用
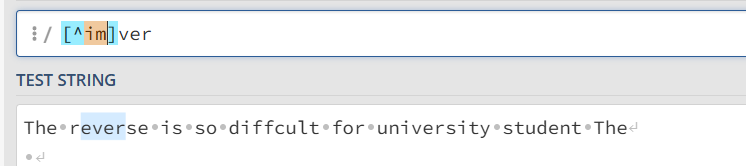
^ 否定字符集
有两个作用,第一个是从每行的开始进行匹配(不常用)^The 就是匹配 The而且必须在每行的开始

另一个就是用于否定字符集 (常用) 用于否定整个字符集
[^im]ver 就是匹配任意 ver 且前面的字符不是 i 也不是 m
* 号多字符匹配
* 号可以将 * 号之前的哪一个字符出现的次数不进行限制
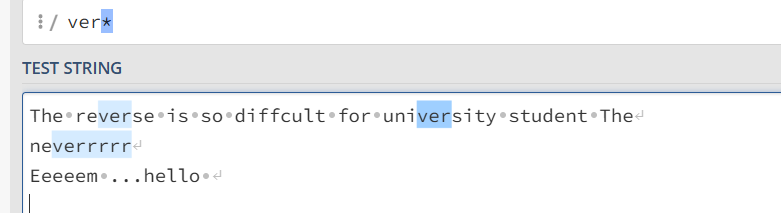
ab* 可以匹配 a ab abb等字符串(字符集也算做一个字符) .*搭配可以通配所有字符

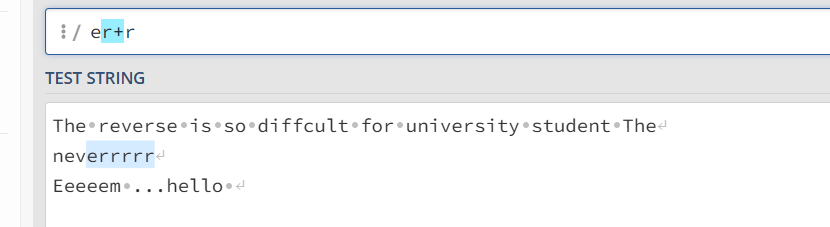
+ 号至少一个字符匹配
加号的前一个字符至少出现一次 er+r 表示e和r之间有一个或者多个r的字符串
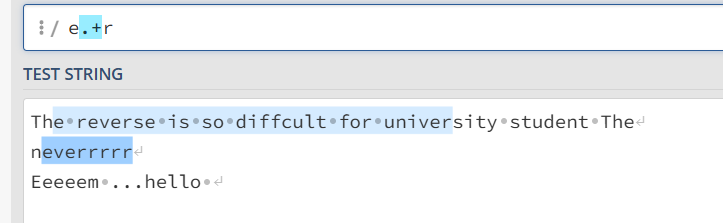
e.+r 表示er中间有字符的所有字符串
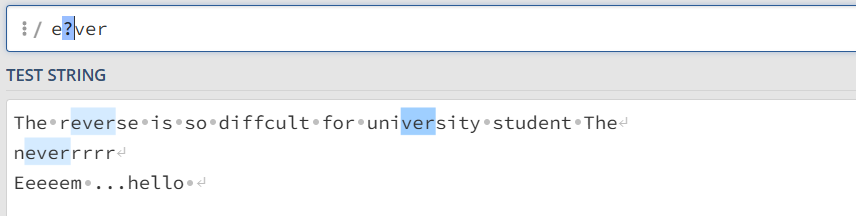
?号表示不定
问号前面的字符可以出现一次或者不出现 [ab]?cd 表示匹配acd bcd cd
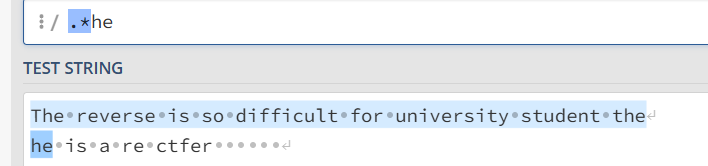
.*re 尽可能长的进行匹配
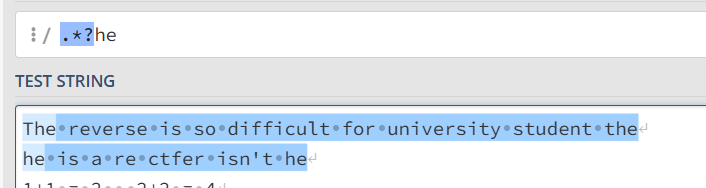
.*?re 尽可能短的进行匹配
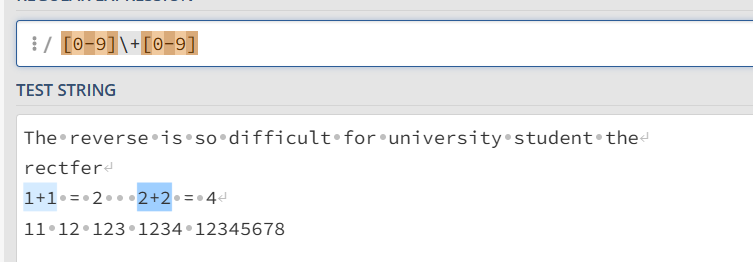
{ } 号 限制次数
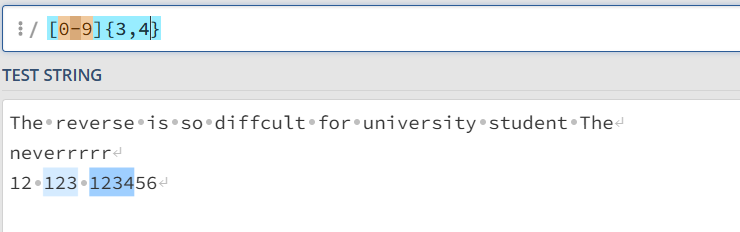
{ }限制前面一个字符出现的次数 { } 的后一个参数可以忽略,或者只写一个参数
[0-9]{4,6} 匹配数字出现4-6次 [0-9]{4, } 匹配数字至少出现4次
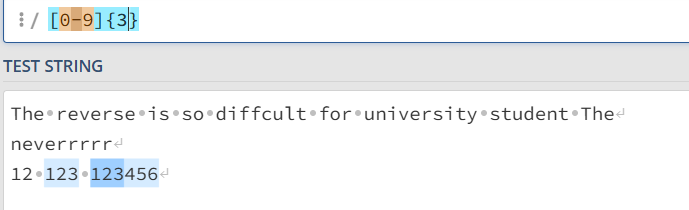
[0-9]{2} 匹配数字出现两次
( ) 括号 特征标群
将内部的所有的字符看做一个整体
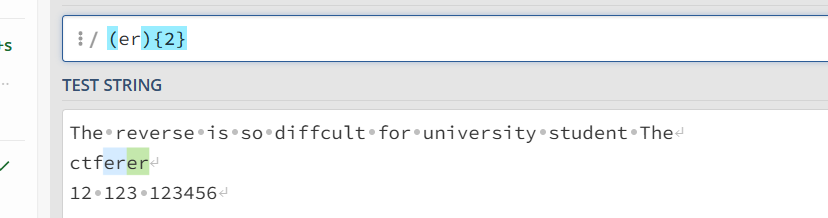
| 或运算符
表示或者 ctf|(T|t)he 表示匹配 ctf 和 (T|t)he 字符串也就是The 和 the
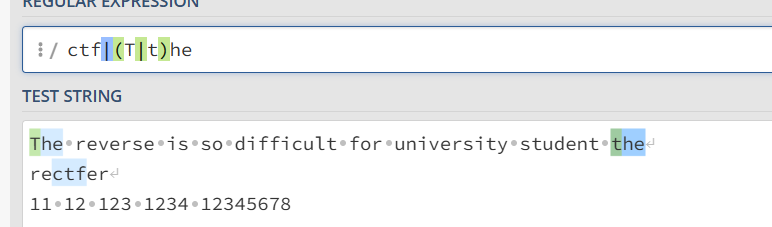
\ 用于转义字符
\. \+ 用于匹配相应的字符
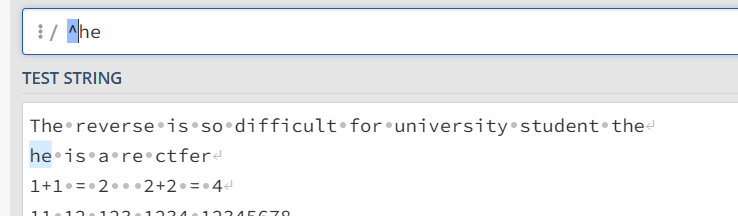
^ 和 $ 指示开头结尾
$ 用于指示一行的结尾,^ 用于指示一行的开头
he$ 表示以he结尾 下图可以很明显的看出

正则语法扩展
字符集的简写
- \w 匹配所有的大小写字母和数字和下划线 [0-9a-zA-z_]
- \W 匹配所有的非大小写字母数字和下划线 [^\w]
- \d 匹配数字 [0-9]
- \D 匹配所有非数字 [^0-9]
- \s 匹配所有空格字符 [\t\n\f\r\p{Z}]
- \S 匹配所有非空格字符 [^\s]
- \f 匹配一个换页符
- \n 匹配一个换行符
- \t 匹配一个制表符
- \v 匹配一个垂直制表符
- \p 匹配\r\n
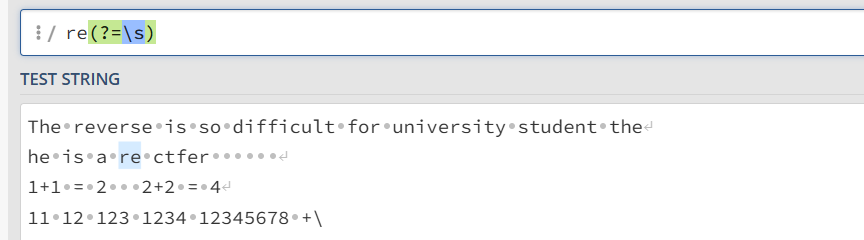
?=xxx 正先行断言
格式为 ?=xxx ,表示符合xxx的字符串 注意该断言只是用来匹配但是不会被纳入最终结果,且在目标字符串之后
re(?=\s) 表示后面跟着空格的 re 字符串
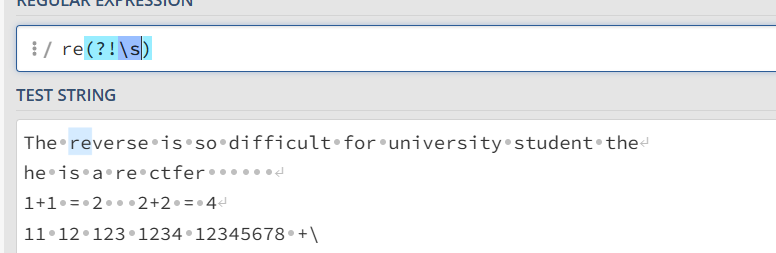
?!xxx 负先行断言
理解上面的正先行,这个的作用就是相反的表示符合xxx之外的
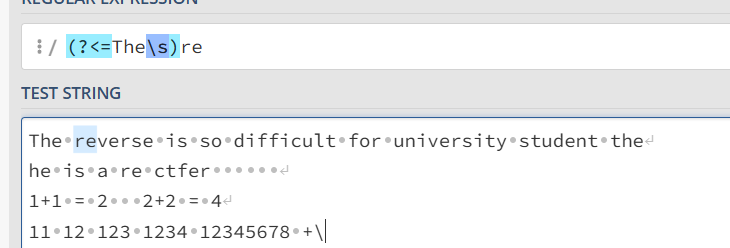
?<=xxx 正后发断言
跟在匹配的字符串的前面
(?<=The\s)re 表示The和空格后面的re字符串
?<!xxx负后发断言
是上一个的非除与断言中匹配的字符串外的字符串

限制
- i 忽略大小写
- g 全局搜索
- m 每行的开头与结尾用 ^ 和 $ 进行匹配
/re/g 全局搜索 re /re/gi 全局搜索并且忽略大小写
如果后面选定了/m那么需要用 ^ 和 $ 符号对每一行的开头与结尾进行匹配
Python re 库实例
常见匹配查询
match 是从头开始比较没找到直接None, search 是从对整个字符串比较, findall 是将所有的符合条件的全部输出出来是一个 list
import re
str1 = "Cats are smarter than dogs \nCtf-all-in-one is useful \nTat rere"
print(str1)
out1 = re.match("[C|T]at",str1)
print(out1,"-->",out1.group()) # <re.Match object; span=(0, 3), match='Cat'> --> Cat
out1 = re.match(".re",str1)
print(out1,"-->") # None -->
out2 = re.search("[C|T]at",str1)
print(out2,"-->",out2.group()) # <re.Match object; span=(0, 3), match='Cat'> --> Cat
out2 = re.search(".re",str1)
print(out2,"-->",out2.group()) # <re.Match object; span=(5, 8), match='are'> --> are
out3 = re.findall("[C|T]at",str1)
print(out3) # ['Cat', 'Tat']re.complie 编译正则
编译一个正则表达式,可以调用其他函数
import re
str1 = "Cats are smarter than dogs 333 \nCtf-all-in-one is useful 111 \nTat rere 222"
print(str1)
patten = re.compile(r"\d+")
out4 = patten.findall(str1)
print(out4) # ['333', '111', '222']
out5 = patten.search(str1)
print(out5,out5.group()) # <re.Match object; span=(27, 30), match='333'> 333re.finditer 迭代器
匹配所有的正则,返回一个迭代器
import re
str1 = "Cats are smarter than dogs 333 \nCtf-all-in-one is useful 111 \nTat rere 222"
print(str1)
out6 = patten.finditer(str1)
for i in out6:
print(i,i.group()) # <re.Match object; span=(27, 30), match='333'> 333
# <re.Match object; span=(57, 60), match='111'> 111
# <re.Match object; span=(71, 74), match='222'> 222
re.sub 替换
import re
str1 = "Cats are smarter than dogs 333 \nCtf-all-in-one is useful 111 \nTat rere 222"
print(str1)
out7 = patten.sub('AAA',str1)
print(out7)
# Cats are smarter than dogs AAA
# Ctf-all-in-one is useful AAA
# Tat rere AAAre.split 分割
import re
str1 = "Cats are smarter than dogs 333 \nCtf-all-in-one is useful 111 \nTat rere 222"
print(str1)
out8 = patten.split(str1)
print(out8) # ['Cats are smarter than dogs ', ' \nCtf-all-in-one is useful ', ' \nTat rere ', '']